
Управление рисками в разработке ПО — это системный процесс идентификации, анализа и минимизации факторов, способных отклонить проект по срокам, бюджету или качеству. По данным PMI, 70% ИТ-проектов сталкиваются с существенными отклонениями, а каждый третий выходит за рамки бюджета более чем на 20%. Ключевые элементы управления: классификация рисков, количественная оценка вероятности и влияния, закладывание резервов, непрерывный мониторинг метрик прогресса и контроль подрядчика. Ниже — практическая схема, которая помогает перейти от интуитивного реагирования к проактивной защите инвестиций.
Статья ориентирована на ИТ-руководителей и заказчиков разработки, которые хотят застраховать проект от типовых провалов. Вы узнаете, как на старте определить критические риски, рассчитать резерв бюджета, выбрать метрики для отслеживания прогресса и выстроить прозрачный контроль подрядчика. Основной акцент — на практических инструментах, применимых в условиях российского рынка 2026 года и отечественных стандартов, таких как ГОСТ 19 ЕСПД на программную документацию и ГОСТ Р 56939 по безопасной разработке.
Раннее внедрение управления рисками снижает стоимость исправлений на порядок: устранение архитектурной ошибки на этапе проектирования обходится в 10 раз дешевле, чем на этапе внедрения. Именно поэтому проактивные стратегии — не дополнительная бюрократия, а прямой вклад в выполнение проекта в срок и в рамках бюджета.
Классификация рисков в ИТ-проектах: от технических до организационных
Эффективное управление начинается с понимания, какие именно угрозы могут повлиять на проект. Без классификации сложно приоритизировать реагирование: команда распыляется на множество мелких страхов, упуская по-настоящему катастрофические сценарии. Ниже — укрупнённые категории, которые полезно проработать до старта разработки.
- Технические риски: архитектурная несовместимость, нестабильность сторонних библиотек, проблемы производительности под нагрузкой, критичные уязвимости безопасности.
- Организационные риски: текучесть кадров, недостаток компетенций в команде, смена приоритетов со стороны бизнеса, затянутые процедуры согласования.
- Внешние риски: изменения нормативной базы (в том числе требования ФСТЭК и Минцифры), санкционные ограничения на импортное ПО, сбои в работе облачной инфраструктуры.
- Рыночные риски: выход конкурентов с аналогичным продуктом, сдвиг ожиданий пользователей, потеря актуальности скоупа к моменту сдачи.
Классификация по ГОСТ Р 56939, если разработка требует оценки безопасности, добавляет категории уязвимостей и угроз, которые необходимо отслеживать на всех этапах жизненного цикла. Даже в типовых проектах полезно выделить как минимум технические и организационные риски — на их долю приходится до 80% причин задержек.

Количественная оценка: переводим риски в деньги и сроки
После классификации каждый риск оценивается по двум параметрам: вероятность наступления и потенциальный ущерб (в деньгах или рабочих днях). Произведение этих величин даёт числовую экспозицию — показатель, на который можно опираться при бюджетировании резервов.
Пример расчёта: риск «уход ключевого разработчика» имеет вероятность 30% и может вызвать задержку в 3 недели. Если заказчик оценивает себестоимость недели простоя в 500 000 рублей, ожидаемые потери составят 0,30 × 3 × 500 000 = 450 000 рублей. Это не гарантированная потеря, а усреднённая оценка, но именно такие цифры служат основой для резервного фонда.
| Степень | Вероятность (описание) | Влияние (описание) | Действие |
|---|---|---|---|
| 1 | Маловероятно (70%) | Критическое (срыв проекта) | Пересмотреть скоуп |
Для вероятности часто используют экспертные оценки: собрание ключевых участников проекта, анонимное анкетирование и усреднение мнений. Точность растёт, если команда опирается на исторические данные — например, частоту сбоев серверов или текучесть персонала за последние два года. Когда детальных данных нет, подойдёт грубая шкала из 3–4 градаций, как в таблице выше.
Инструменты мониторинга и раннего предупреждения
Сам по себе реестр рисков — статичный документ. Чтобы он работал, нужны лёгкие инструменты, которые обновляются на регулярной основе и подсвечивают ухудшающуюся ситуацию. Ниже — минимальный набор, внедрение которого занимает несколько часов.
- Реестр рисков (risk register): таблица с идентификатором, описанием, владельцем, оценкой вероятности/влияния и текущим статусом. Ведётся в Excel, Google Sheets или плагине к трекеру задач.
- Тепловая карта (heat map): двухмерная матрица «вероятность × влияние», где каждый риск отмечен цветом от зелёного до красного. Быстро показывает, сколько угроз требует немедленного внимания.
- График выгорания рисков (risk burndown chart): динамика снижения остаточного риска (в деньгах или баллах) от спринта к спринту. Отклонение от плановой кривой — сигнал к ревизии стратегии реагирования.
Обновление всех трёх документов занимает не более 30 минут в неделю. В Agile-командах естественная точка синхронизации — sprint review или ретроспектива. Для гибридных проектов можно ввести еженедельную «риск-пятиминутку». Цифровые версии предпочтительнее: они доступны всем заинтересованным сторонам и легко интегрируются в дашборды проекта.
Организация контроля подрядчиков: что проверять в отчётах и на код-ревью
Контроль подрядчиков — это не тотальная проверка каждой строки кода, а регулярное подтверждение того, что работа движется в верном направлении и с оговоренным качеством. Без такого контроля риски остаются скрытыми до стадии приёмки, когда исправления стоят максимально дорого.
Ключевые контрольные точки, которые должен запросить заказчик:
- Еженедельный статус-отчёт: обязательно включает бёрндаун-чарт, velocity и список заблокированных задач.
- Sprint Review / демо: работающая версия с возможностью «пощупать» результат, а не слайды.
- Автоматический отчёт о качестве кода: метрики из SonarQube или аналогов — покрытие тестами, дублирование, цикломатическая сложность.
- Журнал инцидентов: все критические дефекты, обнаруженные на проде или стейджинге, с анализом причин.
- Выборочное код-ревью: не реже раза в месяц независимый архитектор или техлид заказчика проверяет наиболее рискованные модули.
| Частота | Что проверять |
|---|---|
| Еженедельно | Статус-отчёт, бёрндаун, список блокеров |
| Каждый спринт | Демо результата, пересмотр velocity |
| Ежемесячно | Дашборд качества кода, объём технического долга |
Формальные отчёты — лишь верхушка айсберга. Заказчику стоит получить прямой доступ к репозиторию и CI/CD-пайплайну, чтобы видеть реальную картину, а не «причёсанную» сводку. Это снижает разрыв между ожиданиями и фактом.
Метрики прогресса разработки: от бёрндаун-чарта до defect leakage
Метрики прогресса разработки служат системой раннего оповещения: отклонение тренда сигнализирует о зреющем риске за несколько недель до того, как он перерастёт в кризис. Ниже — минимальный набор метрик, который стоит отслеживать в любом проекте дольше двух месяцев.
- Бёрндаун-чарт (burndown chart): график остаточного объёма работ против времени. Если фактическая линия систематически уходит выше плановой, проект отстаёт.
- Velocity: средний объём задач (в story points), завершаемый командой за спринт. Падение velocity на 30% и более два спринта подряд — тревожный сигнал.
- Cycle time и Lead time: время от начала работы над задачей до её готовности и время от постановки до сдачи соответственно. Рост этих показателей указывает на пробки в процессе.
- Defect leakage: отношение числа дефектов, найденных после релиза, к общему числу дефектов. Если показатель выше 10%, процессы тестирования требуют усиления.
- Технический долг (technical debt ratio): стоимость устранения самых критичных нарушений качества кода, поделённая на стоимость разработки. Рекомендуется держать показатель ниже 5%.
Метрики должны быть прозрачными для всех сторон. Рекомендуется настроить автоматическую выгрузку в общий дашборд (например, на базе Grafana или аналитического модуля Jira), чтобы исключить ручной сбор и разногласия в цифрах.

Проактивные стратегии: как заказчику повлиять на риски без микроменеджмента
Ожидание финального билда, чтобы проверить результат, — самая дорогая тактика. Превратить её в проактивную помогают шесть действий, доступных заказчику без погружения в микроуправление.
- Фиксируйте скоуп с приоритизацией. Методы MoSCoW или Kano позволяют выделить must-have функции и отсечь второстепенные до лучших времён — это защищает от расползания границ проекта.
- Требуйте регулярные демо. Каждые 1–2 недели предъявляйте работающий инкремент. Даже частично готовая функция, показанная на стенде, выявляет недопонимание спецификации на раннем этапе.
- Настройте CI/CD с автоматическими тестами. Если подрядчик ещё не внедрил конвейер, включите это требование в контракт. Автоматическая проверка сборки и регрессионных тестов снижает риск «битых» билдов.
- Проводите ретроспективы. Раз в спринт встреча с командой, где обсуждаются не только технические, но и организационные проблемы. Заказчик получает объективную картину, а не формальный отчёт.
- Резервируйте время на рефакторинг. После каждого крупного этапа выделяйте 1–2 дня на приведение кода в порядок — это замедляет рост технического долга.
- Привлекайте независимого QA-инженера. Сторонний взгляд на процессы тестирования часто вскрывает системные слабости, незаметные текущей команде.
Ни один из этих шагов не требует присутствия заказчика в опенспейсе команды. Достаточно встроить контрольные точки в календарь проекта и назначить ответственных с обеих сторон.
Резерв бюджета: как рассчитать и когда использовать
Резерв бюджета — это не «лишние деньги», а страховка от тех рисков, которые нельзя предотвратить полностью. Его размер должен вытекать из количественной оценки, а не из эмпирического «плюс 15%». Подробное сравнение методов смотрите в таблице ниже.
Правила расходования резерва должны быть зафиксированы до старта: доступ к средствам открывается только при фактической материализации риска, зафиксированной в журнале инцидентов. Типичный пример: увольнение ведущего разработчика — резерв покрывает затраты на поиск замены и ликвидацию отставания. Расширение скоупа под новую хотелку бизнеса не финансируется из резерва.
План коммуникаций и эскалации при критических отклонениях
Даже лучший мониторинг бесполезен, если о красных триггерах узнают постфактум. План эскалации — это заранее оговорённый алгоритм: кто, кому и в каком формате сообщает о выходе параметров за допустимые пределы.
Пороги эскалации, пригодные для большинства проектов:
- Отклонение по срокам > 10% от плановой длительности этапа.
- Превышение бюджета > 15% от утверждённого на текущий период.
- Снижение velocity команды на 30% и более два спринта подряд.
- Потеря ключевого специалиста (архитектор, техлид, ведущий тестировщик).
Алгоритм настройки плана:
- Определите пороги вместе с подрядчиком и утвердите у спонсора проекта.
- Назначьте владельцев эскалации — по одному ответственному с каждой стороны.
- Зафиксируйте формат коммуникации: экстренное письмо с пометкой «Эскалация», звонок в течение часа, внеплановая встреча не позднее следующего рабочего дня.
- Проведите тестовую эскалацию в первую неделю проекта — это снимает барьеры и выявляет неработающие каналы связи.
Наличие плана дисциплинирует обе стороны: подрядчик знает, что молчание наказуемо, а заказчик получает рычаг влияния без необходимости ежедневного ручного контроля.
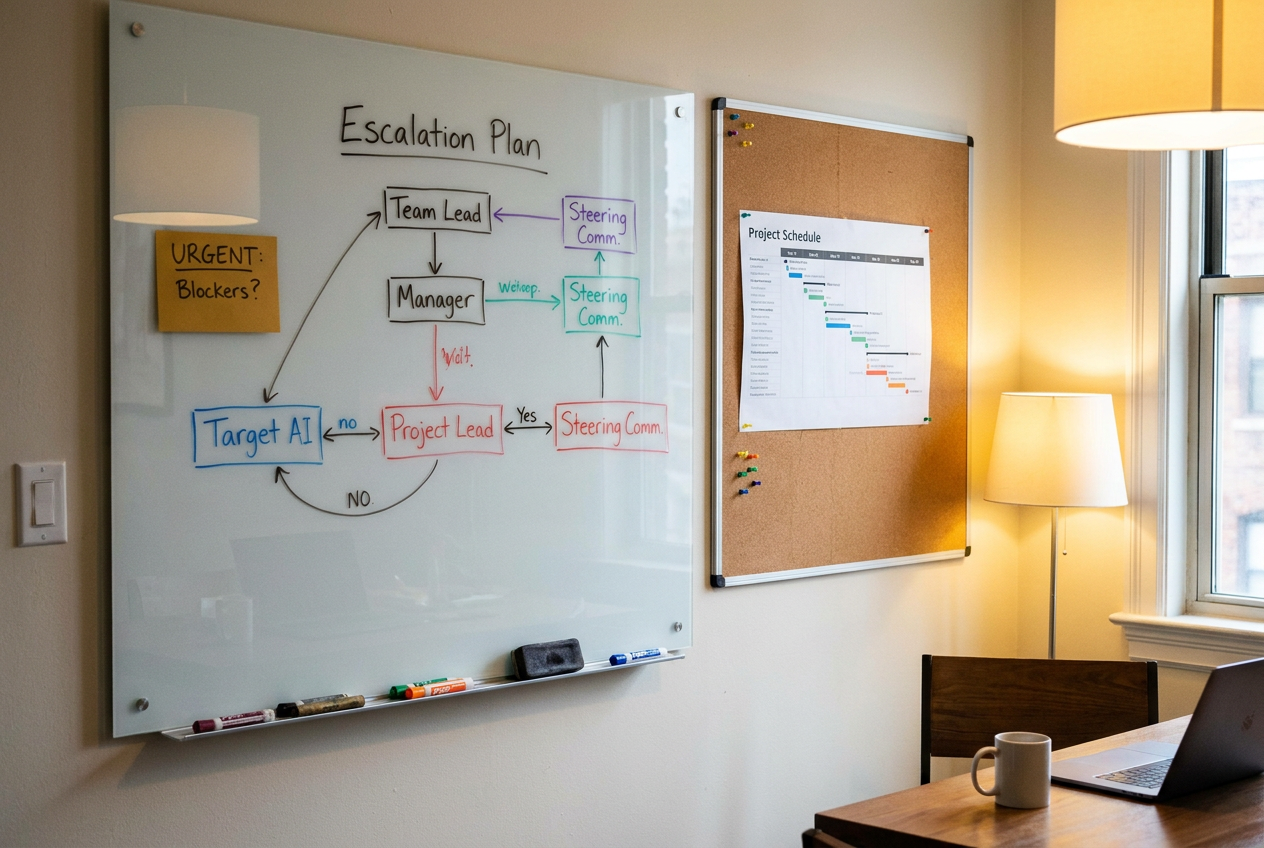
Интеграция управления рисками в жизненный цикл проекта
Управление рисками не существует отдельно от методологии разработки. Встраивание в жизненный цикл гарантирует, что анализ угроз не останется формальностью.
- Waterfall: фаза анализа включает детальную идентификацию рисков; каждые gate review (проверка контрольной точки) сопровождаются обновлением реестра. Управление рисками в разработке ПО здесь тяготеет к документированным процедурам.
- Agile: риски обсуждаются на sprint planning (что может заблокировать работу) и ретроспективе (что пошло не так). Risk burndown chart обновляется после каждого спринта. Гибкость методологии позволяет быстро менять приоритеты при появлении новой угрозы.
- Гибридные подходы: критический скоуп фиксируется с резервами и чёткими порогами эскалации, а экспериментальная часть управляется итерационно — риски на стыке двух частей мониторятся отдельно.
Независимо от выбранной модели, ключевое требование одно — непрерывность. Если реестр рисков обновляется раз в квартал при месячных спринтах, польза от него стремится к нулю.
Чек-лист для заказчика перед стартом нового проекта
Десять пунктов, которые превращают абстрактное «управление рисками» в конкретный список дел на старте:
- Определите аппетит к риску: какой уровень отклонений (сроки, бюджет) допустим для бизнеса?
- Проведите первичную идентификацию рисков совместно с командой подрядчика.
- Классифицируйте и приоритизируйте угрозы, используя матрицу «вероятность × влияние».
- Назначьте владельцев для каждого значимого риска.
- Оцените ожидаемые потери и заложите резерв бюджета.
- Согласуйте метрики прогресса разработки и частоту отчётности.
- Установите пороги эскалации и зафиксируйте их в плане коммуникаций.
- Убедитесь, что контроль подрядчика включает код-ревью и автоматические отчёты о качестве.
- Проверьте соответствие документации ГОСТ 19 и требованиям безопасной разработки по ГОСТ Р 56939, если применимо.
- Запланируйте первый формальный обзор рисков через 2 недели после старта.
Системный подход к управлению рисками снижает вероятность провала и защищает инвестиции.